







As plant research evolves toward high-throughput, real-time data collection, machine learning (ML) has emerged as a transformative tool in phenotyping. From trait classification to yield prediction, machine learning helps researchers unlock insights into the complex interactions between plants and their environments.
In this article, we explore the key questions shaping this field, using real-world case studies and methods that demonstrate how machine learning is changing the way we understand and improve crops.
What are the key machine learning methods used in plant phenotyping?
Several ML methods are widely used in phenotyping:
- Supervised learning (e.g., Support Vector Machines, Random Forests) for classification of traits like drought stress or disease.
- Unsupervised learning (e.g., PCA, k-means clustering) for exploring hidden structures in multi-trait datasets.
- Deep learning, especially Convolutional Neural Networks (CNNs), for automated feature extraction from imaging or time-series sensor data.
- Ensemble methods (e.g., XGBoost) for boosting prediction accuracy in trait modeling and QTL detection.
These techniques allow researchers to analyze both structured data (like transpiration rates) and unstructured data (like hyperspectral images).
What types of data are most effective for training machine learning models in phenotyping?
Highly effective data types include:
- Time-series physiological data (e.g., biomass, transpiration, WUE)


- Environmental conditions (light, temperature, humidity)
- Genetic markers and sequencing data
- Imaging data (RGB, hyperspectral, thermal)
A recently published article (2025) merges high-resolution PlantArray data (e.g., transpiration rate, water-use efficiency) with machine learning models. It demonstrates how feeding rich physiological time-series data into machine learning models significantly improves the prediction accuracy of plant stress indicators, outperforming simpler threshold-based approaches. This integration also enhances early detection and trait prediction by leveraging dynamic measurement patterns and advanced ML analytics.

- The study merges high-resolution PlantArray data (e.g., transpiration rate, water‑use efficiency) with machine learning models.
- Demonstrates how feeding rich physiological time‑series into ML improves prediction accuracy for plant stress indicators, outperforming simpler threshold models.
- Shows improved early detection and trait prediction due to dynamic measurement patterns and ML analytics.
Alperin, H., Tamir, M., Leibman-Markus, M., Tzfadia, O., & Moshelion, M. (2024). Integrating load-cell lysimetry and machine learning for prediction of plant stress responses. bioRxiv.
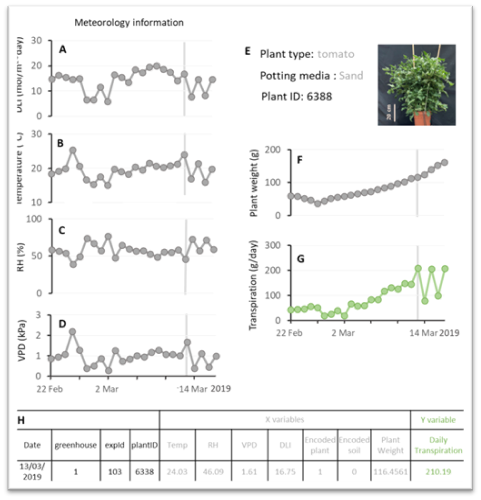
The figure presents representative meteorological and physiological data derived from the I-CORE greenhouse using the PlantArray system, showcasing a single plant as an example over a 22-day experiment. Daily averages include (A) light integral, (B) temperature, (C) relative humidity, and (D) vapor pressure deficit, illustrating the environmental conditions experienced by the plant. Panel (E) provides identity details such as plant type, potting medium, ID number, and a photograph taken at the conclusion of the experiment. Physiological measurements include (F) plant biomass (net weight) and (G) whole-plant daily transpiration, which highlights the system’s sensitivity to methodological changes. Finally, (H) shows a single observation from March 13, visually represented in panels A-F. In this context, gray-labeled variables (X) serve as input features, while the green-labeled variable (Y) acts as the output used in machine learning models for prediction and analysis.
How do I choose the right machine learning algorithm for my phenotyping project?
The choice depends on:
- Data type (structured like sensor data vs. unstructured like images)
- Goal (classification, regression, clustering, or anomaly detection)
- Computational resources and dataset size
- Interpretability (e.g., decision trees are easier to interpret than neural networks)
Tip: Start with a baseline model (like Random Forest), then experiment with more complex models like deep neural networks if performance needs improve.
What are the challenges of implementing machine learning in plant phenotyping?
Some key challenges include:
- Data quality and standardization
- Labeling and annotation effort
- Overfitting with small datasets
- Integrating multiple sensor types
- Limited access to computational infrastructure
However, platforms like PlantArray can reduce variability and improve signal quality by offering clean, repeatable physiological data, which minimizes noise in ML training sets.
Can machine learning be used to predict plant growth and yield outcomes?
Yes – in fact, yield prediction is one of the most active areas of ML in phenotyping. By combining:
- Early-stage physiological traits
- Environmental metrics
- Genomic profiles
ML models can forecast growth patterns and final yield outcomes with increasing accuracy. Using PlantArray data, researchers can train models to correlate early biomass and transpiration dynamics with end-of-season yield.
What role does deep learning play in advanced plant phenotyping systems?
Deep learning enables:
- End-to-end modeling (from raw data to trait prediction)
- Automated feature extraction from image or waveform data
- Multimodal learning, where models analyze images and physiological data together
In the context of functional phenotyping, deep learning can uncover hidden patterns in transpiration curves, growth dynamics, or diurnal stress responses, particularly when paired with systems like PlantArray
Are there open-source machine learning tools available for phenotyping applications?
Yes. Some widely used open-source tools include:
- PlantCV – image analysis library for plant phenotyping
- TensorFlow/Keras – general deep learning frameworks
- scikit-learn – ML toolkit for structured data
- Phenotyper – for statistical QTL analysis
- ImageJ + DeepImageJ – for phenotyping image workflows
These tools support customization and community-driven development, making them accessible to research labs of any size.
Machine learning is not just a trend, it’s becoming essential in next-generation plant phenotyping. From trait prediction to stress detection, its value depends on accurate, continuous data. While deep learning models handle complex image and time-series inputs, platforms like PlantArray enable those models to be trained on clean, physiological signals, bridging the gap between sensor output and actionable insight.
Whether you’re a data scientist, breeder, or research agronomist, integrating machine learning with smart phenotyping platforms will transform the way you approach plant research.